
Que tal gente, el día de hoy quiero hablarles sobre un tema que ya todos conocemos y amamos: High Availability. Todos sabemos que HA ha estado presente desde hace mucho tiempo, para ser exactos fue liberado con la versión 3 de ESX lo que antes de vSphere se conocía como Virtual Infrastructure o VI.
Aunque es muy simple de habilitar y configurar existen múltiples consideraciones o puntos a revisar si es que queremos que vSphere sea capaz de proveer esa alta disponibilidad para nuestro ambiente que todos buscamos. Me decidí a escribir este articulo porque durante muchas de mis escalaciones puedo notar que los clientes no comprenden en su totalidad como funciona HA y esto los puede llegar a poner en un peligro innecesario. Voy a comenzar dando un vistazo rápido y de alto nivel a lo que es vSphere HA, no se tratará de un deepdive si están interesados en realmente meterse a fondo les sugeriría leer los libros de clustering deepdive de Frank Deeneman y Duncan Epping aquí solo revisaremos lo básico para poder tener una discusión de diseño.
¿Como funciona High Availability?
Desde la versión 5.0 de vSphere se maneja una arquitectura de HA basada en FDM o “Fault Domain Manager”, versiones previas usaban AAM o “Automated Availability Manager”. En este articulo estaremos hablando exclusivamente de FDM ya que versiones previas ya no son relevantes.
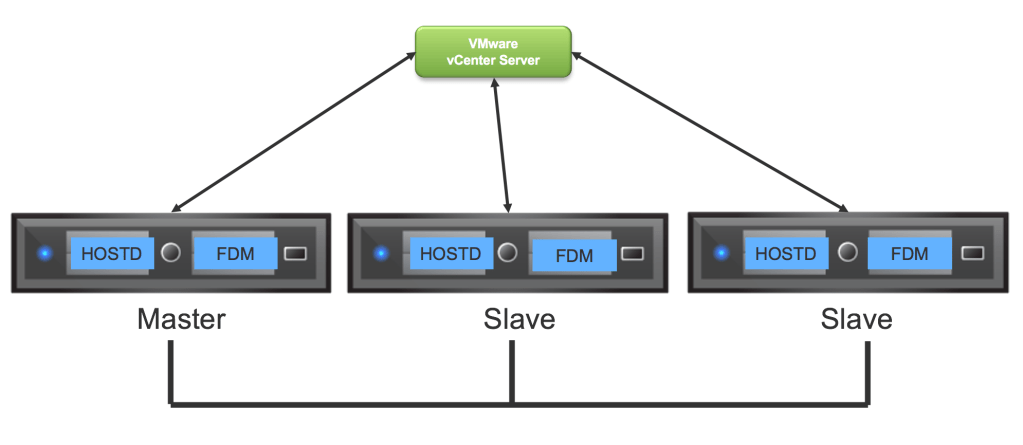
FDM esta compuesto por 3 componentes principales, el agente FDM que corre en cada host ESXi que forma parte de un cluster habilitado con HA, HOSTD que en realidad no es un elemento de FDM per se pero es critico para el buen funcionamiento del mismo ya que provee información de las VMs es están registradas en los hosts ESXi y el tercer elemento es vCenter Server que se encarga de configurar los agentes FDM en los hosts que forman parte de un cluster de HA, comunica los cambios que se han tenido en el cluster y también se encarga de proteger y desproteger las VMs cuando estas son encendidas o apagadas.
La arquitectura de HA esta basada en “Masters” y “Slaves” vamos a ver que es lo que hace cada uno:
- Master – el nodo master se encarga de llevar un registro del estado de las VMs y tomar acción en caso de ser necesario, toma control de las VMs al bloquear el datastore en donde están almacenadas (bloqueando un archivo llamado protectedlist ubicado en la carpeta de HA .vSphere-HA) y toma la acción de reiniciar VMs en caso de una falla. También determina el estado de los nodos “slaves” y lo reporta de vuelta a vCenter Server, en caso de que algún nodo slave este aislado reportara la lista de VMs que estaban siendo ejecutadas en dicho nodo para que puedan ser reiniciadas.
- Slave – En el caso de los nodos slaves las responsabilidades son menores, ellos solo monitorean las VMs que están siendo ejecutadas en ellos y también determinan de manera continua si el nodo master esta disponible o no, en caso de no estar disponible se iniciara un proceso de elección de un nuevo master.
Los diferentes nodos del cluster de HA se comunican de múltiples maneras:
- Archivos locales y remotos – Cada nodo de ESXi que forma parte de un cluster de HA tiene múltiples archivos tanto locales como remotos que incluyen información de las VMs que son ejecutados, sirven para que los slaves puedan notificarle al master que están aislados (en caso de estarlo), configuración del cluster, etc. No vamos a estar ahondando en estos archivos ya que este articulo no es un deepdive de HA sino mas bien recomendaciones de diseño 🙂
- Network Heartbeating – Todos los nodos slave se comunican directamente con el nodo master a través de red para hacerle saber que están “vivos”, el nodo master también envía un heartbeat a cada uno de los nodos slave toda estos flujos de comunicación son de punto a punto entre un slave y el master. Este heartbeat sucede cada segundo y en caso de tener una falla del mismo se tratará de determinar si se trata un evento de isolation.
- Datastore Heartbeating – Este es un segundo mecanismo que nos permite determinar si un host esta realmente aislado o no (isolated), en el caso que el master haya perdido comunicación con uno o mas de los nodos slave este va a leer un archivo llamado “poweron” para ver si este ha sido actualizado por los nodos slave con su estado ya sea aislado o no. En el caso que no tengan Heartbeats de red y que este archivo no haya sido actualizado el master marcara dicho host como fallido. En el caso que este archivo si haya sido actualizado y que se determine que el host esta aislado y/o en una partición de red pero no ha fallado se tomara la acción necesaria con base a lo configurado como “isolation response” que estaremos revisando mas adelante. HA selecciona dos datastores por default que estén disponibles en todos los hosts o en la mayor cantidad de hosts, se puede cambiar la cantidad de Datastores lo cual es necesario para temas de stretched clusters (cosa que no estaremos tocando en este articulo).
Existen múltiples posibles estados de los nodos de HA, vamos a revisarlos para terminar con una perspectiva completa de como funciona HA y ahora si poder tocar temas de diseño ya entendiendo el funcionamiento:
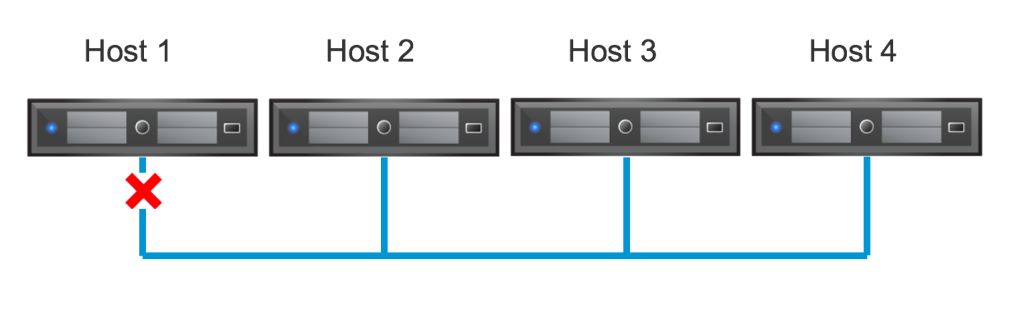
- Isolated (aislado) – En este estado un nodo del cluster HA no puede comunicarse con los otros nodos del mismo cluster, generalmente se habla de un solo nodo, aunque existen situaciones muy especificas donde podríamos tener múltiples nodos aislados:
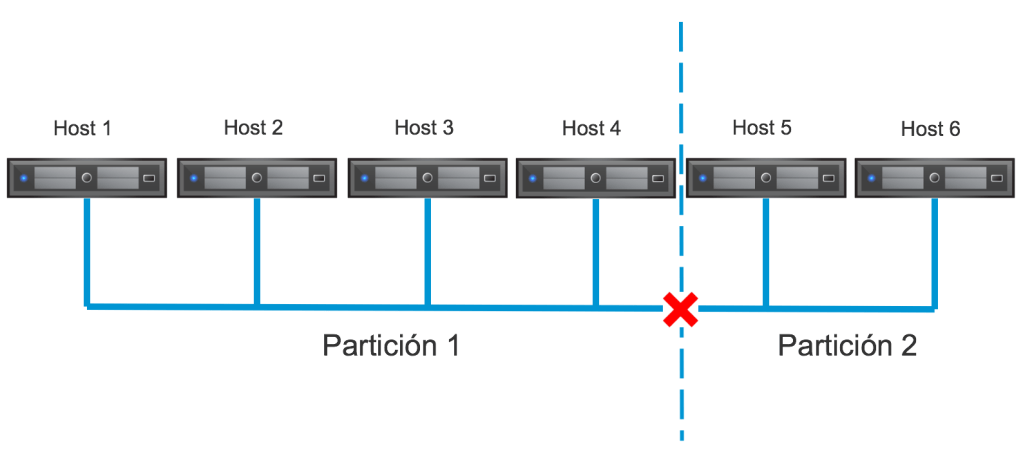
- Partition – En este caso dos o mas nodos pueden comunicarse entre ellos pero no con los demás nodos del cluster, por lo cual se terminan teniendo 2 o mas “particiones”/secciones de la red. En cada partición se elige un master:
Ahora si creo que podemos comenzar a hablar de temas de diseño 🙂 estén pendientes para el siguiente articulo de esta serie donde comenzaremos a tocar temas de diseño. Espero que esta información les sea de utilidad.
